YELLOW PAGES* DE RECURSOS INTERNET
Joaquim Macedo, Maria J. N. Pinto, Miguel Rio, Vasco Freitas
Departamento de Informática
Universidade do Minho
4700-320 Braga,
Portugal
Tel.: +351 253 604470
Fax.: +351 253 604471
Email: {macedo,joao,rio,vf}@di.uminho.pt
Paper presented at the I National WWW Conference - Multimedia Information on the Internet,
Universidade do Minho, Braga, Portugal, Jul 6-8, 1995 (in Portuguese).
Em 12/4/97, substituiu-se neste texto o termo técnico
original em português, por yellow pages, devido ao facto da Empresa
Páginas Amarelas, S.A., uma Empresa da Portugal TELECOM e da ITT World
Directories, ter dirigido uma carta à Universidade do Minho do seguinte teor:
"Tomámos conhecimento que o Departamento de Informática dessa
Universidade está a usar abusivamente a marca Páginas Amarelas (R),
propriedade da nossa Sociedade e devidamente registada no Instituto Nacional de
Propriedade Industrial.
Em face do exposto, solicitamos que cessem de imediato a referida
utilização, sob pena de recurso às vias legais adequadas."
A alteração efectuada não significa o reconhecimento pelos
autores desta reinvidicação.
On the 12/4/97, we replaced in this text the original technical term
in the Portuguese language by the term yellow pages, due to the fact that
the Company Páginas Amarelas, S.A. (páginas=pages, amarelas=yellow),
a Company owned by Portugal TELECOM and ITT World Directories, had addressed a letter
to the Universidade do Minho saying:
"We were let known that the Department of Informatics of that University is abusively
using the trademark Páginas Amarelas (R), a property of our Company and duly
registered at the National Institute of Industrial Property.
In face of the above, we ask you to immediately cease that usage, otherwise legal action
will be taken."
The modification made does not mean that the authors acknowledge the claim.
Keywords: yellow pages, global information infrastructure, indexing, centroids, URI,
resource classification
Palavras chave: yellow pages, Infra-estrutura global de informação, Indexação, Centroids,
URI, Classificação de recursos
Abstract
In this paper we present a strategy for the design and development of a Yellow Pages service of Internet resources which tries to overcome, or at least reduce, the limitations of currently existing services. Referals to classified resources are kept in html pages organised in a hierarchy of titles which may be updated by adding or removing titles.Such a Yellow Pages service is supported by a distributed indexing infrastructure based upon centroid technology allowing for an automatic updating of classified resources. Indexed resources are associated to each title according to a set of predefined requirements.
Because the indexing infrastruture is based upon information provided by the urn2urc service, it is potentially possible to classify all existing network resources.
Resumo
Neste artigo, apresenta-se uma estratégia para a concepção e desenvolvimento de um serviço de Yellow Pages de recursos Internet, em que se tenta ultrapassar, ou pelo menos minimizar as insuficiências dos serviços actualmente existentes. As referências a recursos classificados são mantidas em páginas html organizadas de acordo com uma hierarquia de títulos. Esta pode ser actualizada com a adição ou remoção de títulos.Um tal serviço de Yellow Pages é suportado por uma infra-estrutura de indexação distribuída baseada na tecnologia dos centroids. Este facto permite automatizar a actualização dos recursos classificados. Os recursos indexados são associados a cada título de acordo com um conjunto de requisitos pré-estabelecidos.
Como a infra-estrutura de indexação se baseia na informação disponibilizada pelo serviço urn2urc, considerado indispensável, é potencialmente possível classificar todos os recursos existentes na Rede.
1 - Objectivos
Pretende-se com este trabalho especificar, conceber e posteriormente implementar um serviço de Yellow Pages para os recursos disponíveis na Internet: utilizadores, grupos de discussão, documentos, software serviços, etc... Embora a designação yellow pages seja tradicionalmente usada para hierarquias com apenas um nível de títulos, esta terminologia é aqui utilizada num sentido mais lato.Impõe-se um mecanismo de classificação que possa ser universal, isto é que permita classificar os diversos tipos de recursos disponíveis. São posteriormente colocadas referências para os recursos classificados na hierarquia existente, de acordo com condições de classificação de cada título. O conjunto de condições permite determinar as propriedades dos recursos que, de acordo com o mecanismo de classificação, podem ser referenciados sob esse título. Tipicamente, os recursos de um mesmo título estão organizados por ordem alfabética, embora em alguns casos a localização geográfica possa ser um bom critério de ordenação.
As Yellow Pages devem ser actualizadas automaticamente, no sentido de estarem consistentes com os recursos existentes. Também são necessários mecanismos que permitam a modificação da hierarquia. Essa modificação deverá depender dos recursos classificados (a existência de muitos recursos num mesmo título pode aconselhar o seu refinamento em sub-títulos) e dos utilizadores (mecanismos democráticos à semelhança da hierarquia USENET).
Outra funcionalidade que pode ser importante, embora opcional, é o estabelecimento de relações entre os nós da hierarquia e nós de outras hierarquias de classificação. Isto pode permitir a incorporação de recursos já classificados noutro contexto. O serviço deverá oferecer um mecanismo de [1] navegação através das yellow pages existentes. Um sistema de interrogações para a informação classificada, pode ser uma alternativa à navegação, permitindo ao utilizador o acesso directo à informação.
Neste artigo, parte-se da avaliação das hierarquias de classificação e serviços de indexação actuais, para sintetizar as suas virtualidades no serviço de Yellow Pages a propôr. Futuramente, este serviço será usado para, em face das insuficiências detectadas, ensaiar os mecanismos e soluções adequados à dimensão da Internet.
2 - Estado actual
A grande quantidade de informação presentemente disponibilizada através do WWW e dos restantes serviços de informação Internet, torna indispensável a existência de serviços de indexação e classificação que permitam ao utilizador encontrar o recurso ou informação desejados. A seguir, faz-se uma análise dos serviços de indexação e classificação existentes considerados relevantes, para avaliar em que medida permitem satisfazer as necessidades dos utilizadores.2.1 - Hierarquias de classificação
Consideraram-se os serviços de classificação existentes na Internet e outros considerados relevantes. Relativamente aos serviços da Internet, foram estudadas como hierarquias de classificação outros espaços de informação que não poderiam ser estritamente considerados como tal, mas que utilizam paradigmas de pesquisa de informação semelhantes. A razão principal desta abordagem abrangente é a suposição prévia que este tipo de serviços ainda se encontram numa fase incipiente na Internet.2.1.1 - Yellow Pages Telefónicas e de Fax
A informação disponibilizada nas Yellow Pages corresponde aos números de telefone ou fax de organizações e pessoas. A organização das Yellow Pages[1] é rigorosamente alfabética por títulos representativos das diversas actividades, profissões ou serviços. Existe apenas um nível na hierarquia de títulos. Sob cada título, também em ordem alfabética, encontram-se dispostos os nomes das entidades e pessoas ligadas à actividade enunciada. Para títulos em que a informação tem apenas interesse por localidade, a organização é geográfica.Como determinadas actividades são usualmente conhecidas por mais que uma designação, foram criados títulos remissivos que indicam sob que título deverá ser procurado o serviço ou produto desejado (entradas veja ...) De igual forma, porque há actividades que se relacionam com outras com as quais têm afinidades, existe um segundo tipo de títulos, os títulos relacionados, que lembram a conveniência em consultar os chamados títulos afins (entradas veja também).
2.1.2 - Yellow Pages no WWW
Existe uma grande variedade de sistemas de yellow pages no WWW, todos eles têm o mesmo objectivo: classificar os recursos Internet. Pela grande popularidade que possui, estudou-se com mais detalhe o Yahoo [2] e a sua hierarquia de classificação.O Yahoo é uma base de dados de links para recursos, organizada numa hierarquia de assuntos. Pretende ser uma base de dados genérica com espaço para recursos sobre uma grande variedade de assuntos. A hierarquia de assuntos está pré-definida e não cabe aos utilizadores enriquecê-la. Os recursos são registados manualmente pelos próprios utilizadores do sistema através do preenchimento de um formulário.
Além da possibilidade navegarem pela hierarquia de assuntos, o Yahoo oferece aos utilizadores facilidade de efectuarem interrogações(por palavras chave) à base de recursos registados. Não há qualquer limitação do espaço de pesquisa determinado pela posição do utilizador na hierarquia.
A maior parte dos sistemas de yellow pages estudados têm estas características. Há alguns que utilizam uma hierarquia de classificação que pode ser enriquecida pelos próprios utilizadores do sistema, como por exemplo, a [2]GENVL [3]. A WWW Virtual Library do CERN permite além da navegação, efectuar interrogações em cada nó da hierarquia. Neste caso, o espaço de pesquisa é limitado aos recursos existentes na sub-árvore cuja raiz é o nó onde se faz a interrogação.
2.1.3 - Servidores ftp anónimo e gopher
Nos servidores ftp [4] anónimo e gopher [5] são disponibilizados ficheiros dos mais diversos tipos que vão desde documentos, programas, imagens, etc. A extensão do nome de cada ficheiro é atribuída de acordo com o respectivo tipo. Os diferentes servidores ftp e gopher existentes na Internet são organizados segundo uma determinada hierarquia onde se tenta, de certa forma, fazer uma espécie classificação. Quanto melhor for essa classificação mais intuitivo se torna para os utilizadores encontrar o ficheiro ou a informação desejada. Assim podemos pensar que o pathname de um determinado recurso contém geralmente, de uma forma implícita, informação que pode ajudar na sua classificação. Quando o mesmo recurso é disponibilizado em vários locais com diferentes pathnames essa informação é mais rica. Existem serviços de interrogação para espaços de informação ftp anónimo e gopher, disponibilizados respectivamente pelo Archie [6] e Veronica [7].2.1.4 - News da Usenet
A informação disponibilizada corresponde a artigos de grupos de discussão submetidos pelos utilizadores. A Usenet News [8] é uma hierarquia de milhares grupos de discussão onde se discute tudo o que se possa imaginar! Existem desde grupos para actividades recreativas (REC) até grupos de discussão de assuntos científicos (SCI). As hierarquias vão-se especializando à medida que se criam diferentes grupos de interesse e há métodos democráticos para se criarem novos grupos na hierarquia. Essas regras são estabelecidas para cada hierarquia. A hierarquia tem normalmente um máximo de 5 a 6 níveis.2.1.5 - Bibliotecas
Imagine-se numa biblioteca onde os livros, revistas e outras publicações são colocados aleatoriamente em salas e estantes, sem qualquer catálogo... Perdia-se um tempo infinito para encontrar a informação desejada! Assim as bibliotecas são geralmente organizadas de acordo com uma hierarquia de assuntos extraída de um thesaurus [9]. Para além da ajuda preciosa dos funcionários, a maioria das bibliotecas disponibiliza terminais para interrogação de uma base de dados usando palavras chave, autores, ano de publicação, etc... O serviço de pesquisa oferecido pelas bibliotecas é normalmente designado por [3]OPAC.2.1.6 - Avaliação
Os vários serviços de classificação são usados para um determinado tipo de recursos, tendo um âmbito limitado de utilização. Existem os mais diversos mecanismos de classificação, mesmo para um mesmo tipo de recursos o que faz com que se usem diferentes hierarquias de classificação. A quase inexistência de ferramentas de classificação automáticas dificulta a actualização da informação disponibilizada.A designação de serviço de Yellow Pages, quer nos telefones como no WWW, é usada apenas quando a hierarquia tem apenas um nível de títulos. A hierarquia de classificação pode ser pré-definida ou adaptável aos classificáveis em presença.
Outro aspecto importante é a forma como se detecta a existência de um novo recurso ou modificações na informação dos recursos já classificados. Em todos os sistemas estudados, o registo de novos recursos e a sua actualização é feita pelos utilizadores. Alguns destes serviços oferecem alternativamente um interface para interrogações baseado num serviço de indexação da informação classificada. O espaço de pesquisa pode ser ou não limitado pela posição na hierarquia. Uma síntese comparativa das várias hierarquias estudadas é apresentada no quadro seguinte
Nome |
Yellow pages |
Yahoo | GENVAL | WWW VL | ftp/gopher | news | bibliotecas |
|---|---|---|---|---|---|---|---|
| Tipo de recurso |
organizações pessoas |
documentos organizações pessoas |
documentos organizações pessoas |
documentos organizações pessoas |
documentos software |
artigos em grupos de discussão | publicações |
| Modificação da hierarquia |
fornecedor | fornecedor | utilizadores | fornecedor utilizadores | fornecedor | utilizadores | |
| Atributos de classificação | actividade profissao | tema | tema | tema | tema serviço plataforma autor | tema | tema |
| Classificação do recurso | fornecedor | pessoa que regista | pessoa que regista | pessoa que regista | fornecedor | utilizador | fornecedor |
| Organização no título | alfabética geográfica | alfabética | alfabética | alfabética geográfica | alfabética | data assunto | autor |
| registo de recurso | fornecedor | utilizador | utilizador | utilizador | fornecedor | utilizador | fornecedor |
| Interface de interrogação | sim espaço total |
não | sim | sim Archie Veronica | sim OPAC | ||
| Níveis na hierarquia | 1 | quaisquer | 1 | 3 | quaisquer | quaisquer | quaisquer |
2.2 - Serviços de indexação
Faz-se uma avaliação dos serviços de indexação existentes com base num estudo dos serviços que a este nível pareceram os mais significativos.2.2.1 - ALIWEB, Archie e Veronica
Como o próprio nome indica, o[4] ALIWEB [10] é um sistema inspirado no Archie. Enquanto o Archie é um sistema de indexação dos ficheiros disponíveis nos servidores ftp anónimo, o ALIWEB indexa os recursos disponíveis nos servidores http. Da mesma forma que o Archie, o ALIWEB vai periodicamente buscar a cada servidor http um ficheiro previamente preparado com todos recursos considerados de interesse. Com base nos ficheiros encontrados nos servidores http visitados, constrói ou actualiza a sua base de dados que pode ser pesquisada por um cliente próprio. A lista de recursos é preparada manualmente pelos administradores dos servidores http. Para cada recurso, é necessário preencher um formulário apropriado com alguns atributos, nomeadamente título, descrição e palavras chave. O Veronica é um serviço de indexação análogo para o espaço Gopher.2.2.2 - WAIS
O [5]WAIS [11], é um sistema de publicação electrónica de documentos numa rede de computadores, baseado no modelo cliente-servidor. O cliente é a interface com o utilizador. O utilizador faz interrogações que o cliente traduz e transmite através da rede ao servidor. O servidor interage com uma ou mais base de dados WAIS, também chamadas fontes. Além de indexar as suas bases de dados de forma a conseguir responder rapidamente às interrogações, o servidor é o responsável por ir buscar os documentos completos à base de dados, caso o utilizador assim o deseje.O utilizador pode desejar interrogar um conjunto de fontes, ou até a sua totalidade. Para que isso seja possível sem que o utilizador tenha que memorizar todas as fontes disponíveis, é mantida numa base de dados a descrição de todos servidores WAIS disponíveis. Essa base de dados é indexada por um servidor WAIS, e pode ser interrogada como qualquer outra fonte. Assim, quando o utilizador não sabe qual é a fonte onde está a informação que procura, pode interrogar este servidor e obter uma lista de fontes onde pode encontrar o que deseja.
Qualquer cliente que seja capaz de traduzir as interrogações dos utilizadores para este protocolo pode ser usado neste sistema. Desta forma, através de gateways próprios, é possível aceder ao WAIS usando como interface outros sistemas de informação tais como o gopher, o WWW, etc. Da mesma maneira qualquer servidor pode exportar um índice da sua base de dados para um servidor WAIS. Por exemplo, um servidor http pode, utilizando software específico, exportar um índice das suas páginas html para um servidor WAIS.
2.2.3 - Centroids
A tecnologia dos centroids [12], está em estudo para ser proposta como método normalizado de indexação distribuída na Internet. Um centroid é uma estrutura de dados usada para exportar informação de indexação relativa à base de dados de um determinado servidor.A arquitectura destes sistemas baseia-se em duas componentes: os servidores folha e os servidores de índices.
Os servidores folha interagem directamente com as bases de dados e geram os centroids que exportam para servidores de índices. Estes mantêm os índices que lhes permitem posteriormente direccionar para o servidor adequado as interrogações dos utilizadores. Um centroid de um servidor folha é constituído por uma lista dos registos e respectivos atributos, e por uma lista de palavras por cada atributo. Esta lista de palavras por atributo contém uma ocorrência por cada palavra que aparece pelo menos um vez nos valores desse atributo, em alguma entrada da base de dados desse servidor.
Os centroids dos servidores de índices são baseados na concatenação de todos os centroids que constituem a sua base de dados. O conjunto dos servidores de índices está organizado de forma hierárquica, designado por em directory mesh [13]. O nível mais baixo é constituído pelos servidores em folha e o nível imediatamente acima pelos servidores de índices que contêm os seus centroids, e assim sucessivamente. Desta forma, mantém-se uma infra-estrutura de indexação com capacidade de encaminhar a interrogação [13] do utilizador até ao servidor de informação adequado.
Existe bastante trabalho desenvolvido em torno da tecnologia dos centroids principalmente no âmbito de grupos de trabalho do IETF. Já foram propostos o SOLO [14] e o Whois++ [15], dois protocolos de suporte a serviços de indexação baseados nos centroids. Recentemente, foi proposta uma extensão ao Whois++, o Common Indexing Protocol(CIP) [16]. A ideia subjacente ao CIP é permitir que diferentes protocolos (X.500, Whois++, Solo, LDAP, etc...) usem a mesma infra-estrutura de índices para indexarem a suas bases de dados. Para tal, é necessário que os servidores dos vários protocolos sejam capazes de gerar centroids e possam ser indexados pelos servidores de índices. Desta forma o directory mesh em princípio estará organizado de forma hierárquica, com base na localização dos servidores.
2.2.4 - Avaliação
Do estudo efectuado conclui-se que existem diferentes abordagens quanto à informação que é usada para indexação. Há sistemas que indexam apenas o nome ou título do documento (Archie), sistemas que usam um[6] sumário da informação (ou meta-informação) a respeito do recurso (ALIWEB, Whois++), até sistemas que indexam toda a informação disponível no [7] recurso (WAIS). Também é importante saber se a informação é indexada apenas como um conjunto indiscriminado de palavras chave ou se é indexada de uma forma qualificada isto é em função de determinados atributos da meta-informação.Outro factor de avaliação é a existência ou não de vários níveis de indexação e capacidade de encaminhamento de interrogações [13]. Tendo em conta estes aspectos, foi construído o quadro que se segue em que são sintetizados os vários sistemas de indexação estudados. Embora o OPAC não tenha sido descrito, foi incluído no quadro comparativo.
| Nome | Archie | ALIWEB | Veronica | WAIS | OPAC | Whois++ |
|---|---|---|---|---|---|---|
| Tipo de recurso | recursos FTP | recursos WWW | recursos gopher | documentos | publicações | documentos pessoas organizações outros |
| Fonte para indexação | nome | sumário | nome | texto completo | sumário | sumário |
| Indexação qualificada por atributo | sim nome | não | sim nome | não | sim autor título ano | qualquer |
| Colecção de fontes | ditribuída | ditribuída | ditribuída | ditribuída | centralizada | ditribuída |
| Actualização de índices | centralizada | centralizada | centralizada | ditribuída | manual | ditribuída |
| Hierarquizacao de índices | não | não | não | sim 2 | não | sim qualquer numero |
| Encaminhamento de interrogações | não | não | não | não | não | sim |
2.3 - Discussão geral
A análise dos esquemas de classificação existentes, permite concluir que estes ainda se encontram numa fase bastante incipiente, quer nos aspectos da classificação como na existência de uma abordagem universal e escalável para ser usada na Internet. Outra conclusão importante é a necessidade de tomar como ponto de partida o conhecimento adquirido pelos documentalistas com as modificações exigidas pela universalidade do tipo de recursos e da quantidade de recursos a classificar.Relativamente aos serviços de indexação, a utilização da tecnologia dos centroids, embora ainda numa fase de concepção e desenvolvimento, parece a abordagem adequada para encontrar uma solução para um serviço de indexaçã universal na Internet. Constatada a estreita relação entre os serviços de indexação e hierarquias de classificação e tendo em conta as potencialidades da tecnologia dos centroids, pretende-se neste trabalho desenvolver um serviço de Yellow Pages baseado na tecnologia dos centroids e avaliar as vantagens decorrentes desta abordagem.
3 - Serviço de Indexação de suporte
Nos vários sistemas de indexação e classificação atrás apresentados, a informação fonte poderia ser o nome do recurso, meta-informação sobre o recurso ou a indexação total do próprio recurso. Por qual delas optar? Decidiu-se usar a meta-informação disponibilizada sobre os recursos por uma série de razões:- Usar uma abordagem uniforme na classificação dos diferentes tipos de recursos. Com excepção dos documentos, os restantes recursos não podem ser analisados com base na análise do seu próprio conteúdo.
- A meta-informação sobre os diferentes recursos já tem que ser disponibilizada por serviços básicos, como o serviço de resolução urn2urc. Desta forma a divulgação e a disponibilidade do sistema não dependem da vontade de quem publica os recursos.
- Só desta forma é possível beneficiar das potencialidades de indexação dos centroids.
Para além da infra-estrutura comum de indexação, para que as organizações possam beneficiar das facilidades decorrentes da persistência dos nomes e da transparência de localização e replicação dos recursos de informação da Rede, precisam de efectuar a migração de URLs [18] para os URNs [19] [20]. A seguir, são apresentados os passos necessários nessa direcção.
3.1 - Migração para URNs
Para se efectuar a migração para um serviço de informação baseado em URNs, têm que ser seguidos alguns procedimentos.3.1.1 - Atribuição de URNs
Uma organização que deseje ser responsável pela publicação de documentos, deve dispor de um sistema de atribuição de URNs. Para cada novo recurso tem de haver um processo humano ou automático de lhe atribuir um URN único de forma a ser univocamente identificado. A última parte do URN denominada string opaca [21] apesar de não ter interesse no que toca à resolução urn2urc deverá conter o máximo de meta-informação sobre o recurso.3.1.2 - Serviço de resolução urn2urc
Terá de manter um serviço de resolução baseado, em príncipio, num servidor whois++ responsável por fazer o mapeamento de urns em urcs. Quando precisar de aceder a um recurso, um cliente WWW ou um servidor proxy http, contacta o servidor da organização que publicou o recurso para converter o URN no respectivo URC [22] [20]. O URN deverá conter informação que permita, directa ou indirectamente, determinar o servidor responsável pela manutenção da meta-informação do recurso. Para efeitos de eficiência e tolerância a faltas a organização deverá manter um ou mais servidores secundários com a informação replicada, que consigam responder às mesmas interrogações.
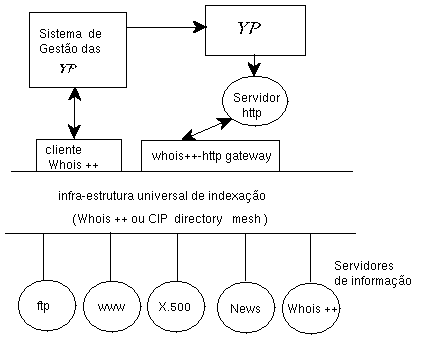
Figura 1: Arquitectura Geral
3.1.3 - Registo de originais e de cópias
Para que os próprios utilizadores possam registar automaticamente os seus documentos deverá ser disponibilizado um interface amigável para que eles próprios introduzam a meta-informação respeitante ao seu recurso. Como já se disse anteriormente, um thesaurus pode ser um recurso bastante útil na validação desta meta-informação, quer verificando a existência das palavras chave, quer acrescentando redundância à meta-informação. Para o registo de cópias são também necessários procedimentos de registo em larga escala para a informação replicada por mirror4 - Utilização de thesaurus
Pelo o que foi dito atrás, estes sistemas devem tomar como ponto de partida a experiência de classificação dos documentalistas . Nesse sentido, a utilização de um thesaurus num sistema deste tipo aumenta substancialmente a qualidade de serviço oferecido. Um thesaurus tem uma função de certo modo inversa à do dicionário. Enquanto este pretende explicar o significado de uma palavra ou termo, o thesaurus pretende ajudar a encontrar a palavra ou termo certo para expressar determinado conceito.Os thesauri são bastante úteis para os diferentes intervenientes no fornecimento da informação em papel ou suporte digital. É por esta razão que constituem há bastante tempo ferramenta importante para a classificação da informação. As entradas do thesaurus são de dois tipos: termos e entradas remissivas (sinónimos). Estas últimas são usadas em referências cruzadas para conduzir o utilizador aos termos mais apropriados. Para permitir vários cenários, os thesauri podem ser organizados em várias partes: thesaurus de termos, índice permutado, índice hierárquico de assuntos, etc...
O thesaurus [9] pode ser bastante útil nos seguintes cenários:
- Na criação da meta-informação, escolher palavras-chave que sejam entradas do thesaurus e colocar a máxima redundância possível (sinónimos, termos relacionados, etc...).
- Utilização à posteriori para avaliar a qualidade da meta-informação disponível.
- Na elaboração das condições de classificação, é de bom tom incluir nas condições os vários sinónimos disponibilizados pelo thesaurus
- Nas interrogações feitas pelos utilizadores, tentar completar com informação disponibilizada pelo thesaurus
- Os títulos, quando fizer sentido (porque há determinado tipo de informação que normalmente não consta do thesaurus) devem ser entradas de nível superior do índice hierárquico do thesaurus. Nesse caso, as condições de classificação podem e devem ter em consideração as entradas subordinadas nesse mesmo índice hierárquico.
- Se se usarem títulos que sejam entradas de um thesaurus, este pode ser utilizado para definir os títulos remissivos e relacionados.
5 - Solução proposta
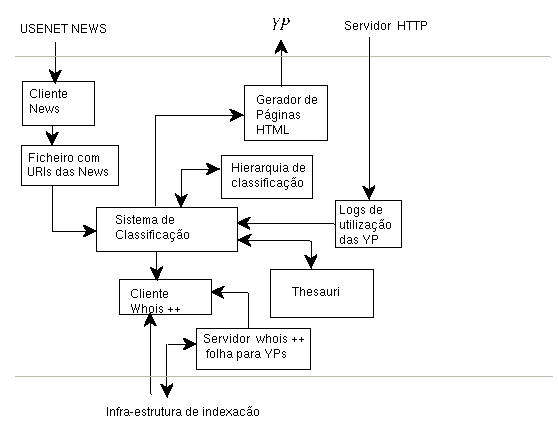
Figura 2: Sistema de Gestão das Yellow Pages
Pretende-se basear este serviço de Yellow Pagesna tecnologia dos centroids de forma a tornar possível a utilização das diversas potencialidades disponíveis. Assim, os componentes fundamentais do sistema proposto são os seguintes (ver figura 1):
- Uma hierarquia de títulos com as condições de classificação para cada nó da hierarquia.
- Um conjunto de páginas html que constituem as yellow pages. O conteúdo dessas páginas são os nomes dos recursos com hiperlinks suportados por URNs ou URLs dos recursos e outras yellow pages.
- A interface de interrogação nessas páginas é suportada por um gateway http-whois++. As interrogações dos utilizadores são qualificadas com condições de acordo com a sua posição na hierarquia. Para além disso são enriquecidas com sinónimos extraídos de um thesaurus.
- Um sistema de gestão que é a componente mais complexa e será detalhado posteriormente. A actualização das yellow pages é feita pelo sistema de gestão que as classifica e coloca os URIs nas yellow pages correctas. Isto é conseguido com interrogações ao directory mesh feitas com ajuda de um cliente whois++.
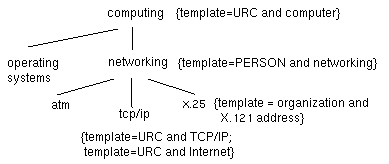
Figura 3:Hierarquia e condições
de classificação
O registo das estatísticas de acesso às yellow pages pode ser tomado em consideração pelo sistema de classificação para alterar a hierarquia de classificação.
5.1 - Hierarquia de classificação
O sistema proposto é independente da hierarquia de classificação escolhida. É, no entanto, apresentado na figura 3 um exemplo com um sub-conjunto da hierarquia, correspondente à "classificação" de computing Podem-se ver representados os nós com os seus títulos, as relações hierárquicas entre eles e, entre chavetas, as condições de classificação de alguns nós. Assim, no nó computing deseja-se ter URCs de documentos sobre computadores, no nó networking pessoas ligadas a redes de computadores e no nó X.25 organizações com endereços X.121. É de salientar que um nó pode ser caracterizado por mais que uma condição de classificação (por exemplo, o nó TCP/IP onde cabem documentos sobre TCP/IP e sobre a Internet).5.2 - Algoritmo de classificação
Classificar os recursos consiste em colocá-los num nó da hierarquia de classificação. Associado a cada título, existe um conjunto de condições de classificação que permite construir as interrogações ao serviço de indexação que, por sua vez, devolve os recursos a colocar nesse nó da hierarquia. Deste modo, quando é obtida a meta-informação sobre um recurso este já está, à priori, classificado no nó cujas condições de classificação deram origem à interrogação. Para evitar que os recursos que já estão num determinado nó façam parte dos seus ascendentes, a árvore é preenchida recursivamente utilizando um percurso pós-fixo e memorizando os URIs colocados em páginas já construídas. Como já foi dito, o sistema assenta no directory-mesh do whois++. Para encontrar recursos o sistema questiona um ou mais servidores whois++. Por exemplo, se fosse feita a seguinte interrogação:whois template=PERSON and networking% 200 Search is executing # FULL PERSON LABCOM1 UM4 NAME: Maria Joao Nicolau INTERESTS: Computer communications and networking POSITION: MSc Student E-MAIL: joao@uminho.pt # END # FULL PERSON LABCOM1 UM3 NAME: Joaquim Macedo POSITION: Lecturer INTERESTS: Computer communications and networking E-MAIL: macedo@uminho.pt # END
5.3 - Actualização das Yellow Pages
Um problema a resolver é a definição do mecanismo a utilizar para manter as yellow pages actualizadas. Encontraram-se duas abordagens alternativas para fazê-lo:- Programa para preenchimento das yellow pages
- Yellow pages suportadas por um mecanismo de caching
Esta abordagem tem a vantagem de dispensar o mecanismo de caching de interrogações. Como desvantagem, assinale-se o facto de ser necessário manter toda a informação nas Yellow Pages, inclusivé nas que nunca foram acedidas.
Na segunda abordagem, uma página amarela é actualizada quando algum utilizador acede pela primeira vez ou quando é necessário actualizar a informação mantida em cache Embora seja a solução mais simples, baseia-se num mecanismo de caching de interrogações, problema esse que ainda não está resolvido nos servidores proxy Presentemente não é guardada informação para URLs que correspondam a interrogações. Esta análise fez-nos optar, pelo menos numa primeira fase, pela primeira abordagem.
5.4 - Yellow Pages Distribuídas
Suponhamos que temos várias organizações com o serviço de urn2urc em perfeito funcionamento e o seu servidor whois++ integrado no whois++ directory mesh. Se cada organização mantiver o seu serviço de yellow pages anteriormente apresentado e catalogar os seus recursos usando uma mesma hierarquia e o mesmo algoritmo de classificação (baseado na colocação de condições nos vários nós da hierarquia), bastará haver um sistema apropriado de mirroring de URIs nos vários títulos da hierarquia para que conjuntamente os vários servidores forneçam um serviço de yellow pages.Cada sistema de yellow pages terá nesse caso de interrogar o servidor whois++ local. Se um servidor pretender classificar recursos de várias organizações, bastará interrogar o whois++ directory mesh com as restrições apropriadas. Com essa abordagem é possível por exêmplo ter um serviço de Yellow Pagesa nível mundial baseado num conjunto de servidores de yellow pages por país. Em resumo, com apenas algumas alterações pode suportar um serviço de Yellow Pages distribuído.
6 - Avaliação do serviço proposto
Os módulos componentes do sistema proposto ainda não se encontram implementados na sua totalidade, pelo que é difícil a avaliação global. Pela simplicidade dos aspectos a implementar, as dificuldades principais prendem-se principalmente com o estado preliminar do software de indexação disponível. Outro obstáculo importante a transpor é o da existência de um thesaurus actualizado e organizado nas partes indispensáveis aos vários cenários de utilização. Os que estão acessíveis na rede são bastante antigos e incompletos. Por este motivo, não se dispõe presentemente de dados de avaliação quantitativos mas apenas qualitativos.Podem-se enumerar as seguintes vantagens, relativamente a serviços de yellow pages existentes:
- Pelo facto de ser baseado numa infra-estrutura universal de indexação, o espaço de recursos classificáveis é maior e mais diversificado. Pode-se pensar na potencial classificação de todos os recursos disponíveis na Rede.
- Permite explorar a possibilidade de caminhar em direcção à automatização da classificação e incorporação de novos recursos já que a meta-informação utilizada para esse efeito é disponibilizada por um serviço indispensável que é a resolução de URNs em URCs.
- O sistema pode suportar um serviço de Yellow Pages distribuído com algumas modificações pontuais.
Nome |
Sistema proposto |
|---|---|
| Tipo de recurso | pessoas organizações documentos outros |
| Modificação da hierarquia |
Trabalho futuro |
| Atributos de classificação |
qualquer um incluído nos registos existentes |
| Classificação do recurso |
fornecedor |
| Organização alfabética |
alfabética geográfica |
| registo de recurso |
importado de urn2urc |
| Interface de interrogação |
Sim Whois++ ou CIP |
| Níveis na hierarquia |
quaisquer |
A chave das vantagens deste sistema relativamente aos existentes tem a ver com o facto de ser suportado por uma tecnologia de indexação concebida para a Internet. De facto, se considerarmos os centroids com um mecanismo de troca de informação de encaminhamento entre servidores de [8] índices, podem ser estabelecidas analogias interessantes com técnicas e mecanismos tradicionalmente usados na camada de rede Internet, nomeadamente o controlo da propagação da informação de encaminhamento. Se se colocarem restrições temáticas na exportação de centroids, utilizando informação retirada dos thesauri, pode-se estudar a viabilidade de construir um directory mesh temático e diluir, cada vez mais, as fronteiras entre a indexação e a classificação. Outra possibilidade é estabelecer essas restrições com base no interesses dos utilizadores.
7 - Trabalho futuro
A avaliação qualitativa deste sistema é bastante favorável, mas os requisitos de indexação limitam bastante a possibilidade de utilização imediata. Daí que haja necessidade de emular a infra-estrutura de indexação com outras ferramentas correntemente em largo uso que permitam a colecção da meta-informação necessária ao seu funcionamento: registo pelos utilizadores, geração de URCs da informação nos mirrors uso de robots nos vários espaços de informação, etc... Só assim será possível ter o sistema em funcionamento real durante o período de migração para os URNs. A exploração da utilização dos thesauri é uma direcção bastante complexa mas prometedora na evolução deste sistema. Precisam de ser estudados e introduzidos no sistema mecanismos que permitam adequar a hierarquia de títulos aos recursos classificáveis e aos interesses dos utilizadores. Finalmente, outra direcção de desenvolvimento é o estudo de mecanismos para controlo e filtragem da informação trocada para encaminhamento de interrogações.Referências:
[1]Portugal Telecom. Yellow Pages (leia-se em português), Portugal Telecom, 1995.[2] David Filo and Jerry Yang. The yahoo directory. , 1995.
[3] Oliver A. McBryan. Genvl and wwww: Tools for taming the web. , In Proceedings of the First International World Wide Web Conference. CERN, May 1994.
[4] J. Postel and J. Reynolds. Rfc 959 file transfer protocol. , October 1985.
[5] F. Anklesaria, M. McCaHill, P. Lindner, D. Johnson, D. Torrey, and B. Alberti. Rfc 1436 - the internet gopher protocol (a distributed document search and retrieval protocol). , March 1993.
[6] Peter Deutsch and Alan Emtage. The archie system: An internet electronic directory service. ConneXions, vol.6, No.2, February 1992.
[7] Steve Foster and Fred Barrie. Frequently Asked Questions about Veronica. July 1994.
[8] Timo Salmi. Frequently Asked Questions about USENET. May 1995.
[9] Engineers Joint Council. Thesaurus of Engineering and Scientific Terms. Engineers Joint Council, 1969.
[10] Martijn Koster. Aliweb - archie-like indexing in the web. , March 1994.
[11] M. St. Pierre, J.Fullton, K. Gamiel, J. Goldman, B. Kahle, J. Kunze, H.Morris, and F. Schiettecatte. Wais over z39.50-1988. , June 1994.
[12] Chris Weider, Jim Fulltom, and Simon Spero. Architecture of the whois++ index service, internet draft (work in progress). , March 1995.
[13] P. Falstrom, R. Schoultz, and C. Weider. How to interact with the whois++ mesh, internet draft (work in progress). , March 1995.
[14] C. Huitema, P-A. Pays, A. Zahm, and A. Woermann. Simple object look-up protocol, internet draft (work in progress). , June 1994.
[15] Peter Deutsch, Rickard Schoultz, Patrik Falstrom, and Chris Weider. Architecture of the whois++ service, internet draft (work in progress). , March 1995.
[16] Chris Weider. The common indexing protocol, internet draft (work in progress). , March 1995.
[17] Paul E. Hoffman and Ron Daniel Jr. Urn resolution overview, internet draft (work in progress). , April 1995.
[18] T. Berners-Lee. Rfc 1738 - uniform resource locators (url). , December 1994.
[19] Paul E. Hoffman and Ron Daniel Jr. Generic urn sintax, internet draft (work in progress). , April 1995.
[20] Ron Daniel Jr. and Michael Mealling. Urc scenarios and requirements, internet draft (work in progress). , March 1995.
[21] Paul E. Hoffman and Ron Daniel Jr. x-dns-2 urn scheme, internet draft (work in progress). , April 1995.
[22] Ron Daniel Jr. An sgml-based urc service, internet draft (work in progress). , June 1995.
[23] Miguel Rio, Antonio Costa, Joaquim Macedo, and Vasco Freitas. A framework for the broadcasting and management of uris. , In JENC6 Conference Proceedings. TERENA, May 1995.
[24] Miguel Rio, Antonio Costa, Joaquim Macedo, and Vasco Freitas. Supporting uri infrastructure using message broadcasting. , To appear in INET'95 Hypermedia Conference Proceedings. ISOC, 1995.
Notas de rodapé
[1] browsing, na terminologia inglesa[2] Generate Virtual Library
[3] On-Line Public Access Catalog.
[4] Archie-Like Indexing indexing in the WEB
[5] Wide Area Information System
[6] meta-index
[7] full-text index
[8] que são routers de interrogações